
머신러닝에서 활용할 수 있는 feature들의 속성 타입은 크게 범주형, 수치형 변수이다.
수치형 변수들은 말그대로 숫자로 표시하고, 그 자체가 의미를 가지고 머신러닝의 feature로 바로 활용할 수 있다.
반면에, 범주형 데이터는 대부분의 머신러닝 알고리즘에서 직접적으로 변수로 사용할 수 없고, 임의의 수치로 변환이 되어야만 사용을 할 수 있다. 오늘은 범주형 변수를 수치로 인코딩하는 다양한 방법들과 어떤 경우에 어떤 인코딩 방법이 효과적인지 살펴보도록 하자.
범주형 데이터 분류
범주형 데이터는 두가지로 분류를 할 수 있다.

명목형(Norminal) : 순서가 존재하지 않음
필기도구 : 펜, 연필, 지우개
동물 : 소, 개, 고양이
순서형(Ordinal) : 순서가 존재함
높이 : 낮음 -> 중간 -> 높음
설문 조사 양식에서 질문에 동의하는 정도 : 1~5
인코딩 종류
먼저 인코딩 종류를 알아보기 전에 데이터셋을 가정해보자.

target인 label은 0이나 1로 존재하며, target을 설명해주는 변수인 온도, 컬러의 범주형 feature들이 있다.
이것을 파이썬 코드의 dataframe으로 표현하면 다음과 같다.
import pandas as pd
import numpy as np
data = {'Temperature': ['Hot', 'Cold', 'Very Hot', 'Warm','Hot','Warm','Warm','Hot','Hot','Cold'],
'Color': ['Red','Yellow','Blue','Blue','Red','Yellow','Red', 'Yellow', 'Yellow','Yellow'],
'Target': [1,1,1,0,1,0,1,0,1,1]}
df = pd.DataFrame(data,columns=['Temperature','Color','Target'])범주형 변수의 인코딩 실습을 위해 우리는 pandas, scikit-learn, scikit-learn에 있는 category_encoders 라이브러리를 사용할 것이다.
1. One Hot Encoding
이 방법은 각각의 범주값을 벡터로서 0이나 1의 값으로 각각 별개의 feature로 표현하는 것이다. 이 벡터값의 개수는 해당 범주형 변수에 존재하는 데이터 값의 카디널리티의 개수만큼 feature가 생성될 것이다. 이 방법은 범주형 변수가 치환된 feature의 개수가 많아질수록 머신러닝의 학습 속도를 크게 저하를 시키고 데이터를 메모리에 올려놓고 연산하는 알고리즘들의 경우에 많은 메모리를 잡아먹게 될 것이다.
이 인코딩을 위해서 pandas에서는 get_dummies 기능으로 값을 만들어줄 수 있다. 다음은 샘플 데이터 프레임 코드이다.
df = pd.get_dummies(df, prefix=['Temp'], columns=['Temperature'])
df데이터셋을 기반으로 온도 칼럼에 대해서 여러개의 칼럼으로 one-hot encoding된 dataframe 형식의 데이터가 나온것을 볼 수 있다.

Scikit-learn에는 이를 위한 OneHotEncoder가 있지만 그 자체가 feature 칼럼을 생성하지는 않는다.
그래서 변환한 matrix를 가지고 dataframe을 만들어서 기존 dataframe에 합쳐 넣는 방식으로 위와 같은 dataframe 포멧이 만들어 지게 된다. 코드를 보자.
from sklearn.preprocessing import OneHotEncoder
ohc = OneHotEncoder(categories='auto')
ohe = ohc.fit_transform(df.Temperature.values.reshape(-1,1)).toarray()
dfOneHot = pd.DataFrame(ohe, columns = ["Temp_" + str(ohc.categories_[0][i])
for i in range(len(ohc.categories_[0]))])
dfh = pd.concat([df,dfOneHot], axis = 1)
dfh낮은 버전의 sklearn 라이브러리에서는 기능이 동작하지 않을 수 있는데 0.24.2 버전에서는 제대로 테스트가 되었다.
one-hot encoding은 매우 인기있고 일반적인 방법이다. 우리는 모든 카테고리를 N-1(N은 카테고리가 없음을 포함)개의 인코딩된 feature값으로 사용할 수 있고, 회귀 모델에서는 이것을 사용한다. 하지만, 분류 모델의 경우에는 특히 트리 기반의 알고리즘의 경우에는 사용할 수 있는 모든 변수값을 사용하는게 좋아 N개의 칼럼을 사용하는 것이 좋다. 참고 블로그에서는 이렇게 설명하고 있는데 이건 데이터셋에서 카테고리가 존재하지 않는 경우가 없는 경우에는 신경쓰지 않아도 좋을 것 같다.
이 one-hot encoding 방법은 모든 머신러닝 알고리즘에서 범용적으로 사용이 가능한데, SVM이나 딥러닝, 클러스터링 알고리즘에서도 사용할 수 있다.
다른 문서에서는 one-hot-encoding을 트리 베이스의 앙상블 모델에서는 사용하지 말라고 소개를 하고 있는데 sprase Decision Tree가 생기는 문제때문에 그렇다고 한다. 딥러닝에서도 sprase matrix 문제때문에 임베딩을 하는 등의 벡터값을 다시 만들어 사용하고 있는 것을 보면 이해가 되기는 한다.

2. Label Encoding
이 인코딩 방법은 서로 다른 범주값에 대해 1부터 N까지의 값으로 임의로 표현하는것이다.
숫자는 범주형 변수를 표현할 관계나 순서는 따로 없지만 데이터셋에 존재하는 값의 순서대로 값을 매기는 것이다.
예를 들어 데이터셋에서 순서대로 중복을 제외하고 Cold<Hot<Very Hot<Warm 순서로 나왔다고 했을때 0 < 1 <2 < 3으로 표현하는 것이다.
from sklearn.preprocessing import LabelEncoder
df['Temp_label_encoded'] = LabelEncoder().fit_transform(df.Temperature)
df
3. Ordinary Encoding
변수의 인코딩이 순서가 의미가 있는 특성을 가지는 경우 이 인코딩 값을 사용한다.
머신러닝 알고리즘에서는 이렇게 만들어진 값을 수치 데이터에 대한 순서 정보로 학습이 될 것이기 때문에 명목형 타입의 범주형 변수로는 이렇게 만들지 말고 순서형 변수를 이렇게 만들어 볼 것을 권장한다. 예시로 보면 온도를 표현할때 Cold, Warm, Hot, Very Hot이 있을 때, 뜨거운 정도를 feature로 0, 1, 2, 3의 값으로 바꾸어 표현하는 것이라고 볼 수 있다.
temp_dict = { 'Cold': 1, 'Warm': 2, 'Hot': 3, 'Very Hot': 4}
df['Temp_Ordinal'] = df.Temperature.map(temp_dict)
df
4. Helmert Encoding
Helmert 인코딩은 특정 수준의 종속변수의 평균을 종속변수의 이전 수준의 종속변수의 평균과 비교하는 것이다.
이해가 잘 안가는데 특정 범주형 변수의 종속변수 평균과 이전에 등장했던 다른 변수의 종속변수의 평균값을 비교한다는 것 정도로 이해했다. 다른 글에서는 이 인코딩 방식은 범주형 변수가 Ordinary의 특성을 가지는 경우에 좋다고 얘기를 하고 있다. 이전의 값의 평균을 계산하느냐 이후의 값의 평균을 계산하느냐에 따라 reverse와 forward 방식으로 나뉘는듯 하다.
import category_encoders as ce
encoder = ce.HelmertEncoder(cols=['Temperature'], drop_invariant=True)
dfh = encoder.fit_transform(df['Temperature'])
df = pd.concat([df, dfh], axis=1)
df
5. Binary Encoding
Binary Encoding은 범주값을 이진수의 각 자리수를 feature로 표현하는 것이다. 이것은 one-hot encoding과 비교해보면 feature의 개수가 훨씬 줄어들어 연산량을 줄이고자 할때 효과적이다. 예를 들어 100개의 범주값을 가진 변수가 있는 경우 one-hot encoding은 100개의 feature가 필요하지만 binary encoding을 하면 2^7으로 계산하여 7개의 feature만 있어도 각자 다른값으로 표현이 가능하다.
다음은 그림으로 표현한 예시다.
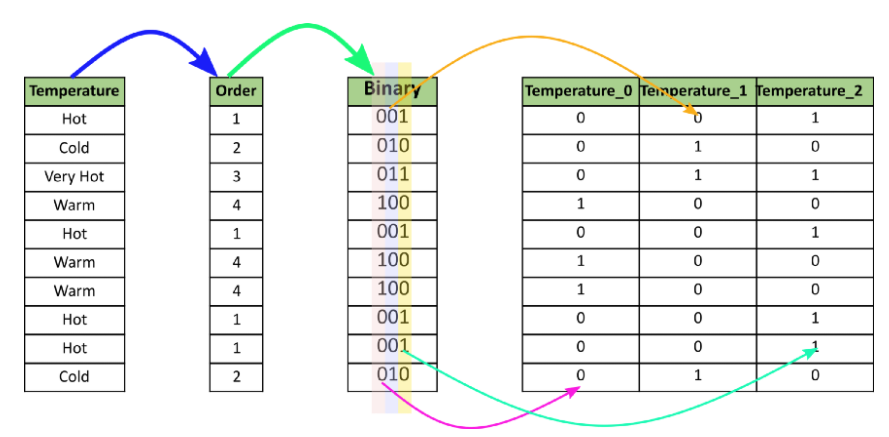
코드는 다음과 같다.
import category_encoders as ce
encoder = ce.BinaryEncoder(cols=['Temperature'])
dfbin = encoder.fit_transform(df['Temperature'])
df = pd.concat([df, dfbin], axis=1)
df
6. Frequency Encoding
범주형 변수의 각 범주값의 빈도수를 label로 활용하고자 하는 방법이다. 빈도수를 기반으로 봤을때 종속변수와 관련이 있는 경우 그런 데이터의 특성을 가중치로 활용하고 할당하는데 도움이 된다.
범주형 변수를 그룹핑하고 각 범주의 개수를 구하고 전체 행의 갯수로 나눠서 구하면 된다.
pandas 코드로는 다음과 같다.
fe = df.groupby('Temperature').size()/len(df)
df.loc[:, 'Temp_ferq_encode'] = df['Temperature'].map(fe)
df결과는 다음과 같이나온다.

7. Mean Encoding 또는 Target Encoding
Mean Encoding은 범주형 변수의 각 범주값을 종속변수 label과 연관시키는 것이다.
이 방법은 데이터의 양에 상관없이 빠른 학습에 도움이 된다. 그리고 일반적으로는 과적합이 될 가능성이 높다고 한다.
그래서 학습 데이터를 교차검증하거나 나온 값을 정규화하는 것이 필요하다.
여러 가지의 변형이 존재하지만 여기서는 두가지 방법에 대해서만 소개한다.
첫번째로 기본적인 방법으로는 학습 데이터에서 각 범주값에 해당하는 label의 합을 label의 개수로 나눠서 구하는 것이다. 예시 그림을 보면 쉽게 이해할 수 있다.

이것의 예시 코드와 결과의 그림은 다음과 같다.
mean_encode = df.groupby('Temperature')['Target'].mean()
print(mean_encode)
df.loc[:, 'Temperature_mean_enc'] = df['Temperature'].map(mean_encode)
df
두번째 버전으로는 Smooting을 하는 방법이다.
이 방법은 각 범주값의 평균의 편차를 좀 더 부드럽게 만들어주는 방법이다.
# Compute the global mean
mean = df['Target'].mean()
# Compute the number of values and the mean of each group
agg = df.groupby('Temperature')['Target'].agg(['count','mean'])
counts = agg['count']
means = agg['mean']
weight = 100
# Compute the 'smoothed' means
smooth = (counts * means + weight * mean) / (counts + weight)
# Replace each value by the according smoothed mean
print(smooth)
df.loc[:, 'Temperature_smean_enc'] = df['Temperature'].map(smooth)
df
8. Weight of Evidence Encoding
WoE 인코딩 방법은 좋고 나쁨에 대한 분리하는 그룹핑 기술이다. 이 방법은 주로 신용 및 금융 산업에서 대출 불이행 위험을 평가하기 위한 예측 모델을 구축하기 위해 만들어졌다. 어떤 가설이 있을 때 feature가 가설을 부합시키거나 약화시키는 정도를 비교해 측정한다.
다음의 식을 보자.

확률로 볼때 P(Goods)와 P(Bads)의 확률이 같다면 ln(1)*100=0 값이 되고 이 그룹은 랜덤과 같다.
P(Bads) > P(Goods)이라면 0보다 작은 음수값을 가질 것이다. 반대이면 0보다 큰 값이 될것이다.
WoE의 식은 확률의 로그값으로 시그모이드 함수(로짓변환)이기 때문에 로지스틱 회귀분석에 적합하다.
학습데이터의 종속 변수값을 사용해 해당 범주값의 데이터별로 직접 비교하여 산출하게 된다. label값을 각 범주값을 판단하는 요소로 활용하기 때문에 frequency encoding과 mean encoding과 비슷하지만 분산값을 더 극적으로 만드는 역할을 하는 것 같다.
WoE의 장점
1. 종속 변수와 독립 변수(범주형 데이터)와의 관계를 단순 label을 다는 것과 대비하여 로지스틱 척도로 극적으로 feature를 생성해주는 이점이 있다.
2. 범주값 종류가 많고 각 값이 적은 경우 비슷한 특성으로 범주값을 그룹핑하는 효과가 있어 전체 범주에 대한 정보를 표현할 수 있다.
3. WoE는 표준화된 값이기 때문에 각기 다른 범주형 데이터에 대해 종속변수에 미치는 범주형 변수간의 Woe를 비교해볼 수 있다.
WoE의 단점
1. 값을 종속 변수에 맞춰 변환하기 때문에 정보 손실이 발생한다.
2. 그렇기 때문에 또한 독립 변수 간의 상관관계가 고려되지 않는다.
3. 그래서 과적합이 발생하기 쉽다.
코드로 예시를 살펴보자.
# We calcuate probablity of target = 1 i.e. Good = 1 for each category
woe_df = df.groupby('Temperature')['Target'].mean()
woe_df = pd.DataFrame(woe_df)
#Rename the column name to 'Good' to Keep it consistent with formula for easy understanding
woe_df = woe_df.rename(columns = {'Target':'Good'})
# Calculate Bad probability which is 1 - Good probability
woe_df['Bad'] = 1 - woe_df.Good
# We need to add a small value to avoid divide by zero in denominator
woe_df['Bad'] = np.where(woe_df['Bad'] == 0, 0.000001, woe_df['Bad'])
# compute the WoE
woe_df['WoE'] = np.log(woe_df.Good/woe_df.Bad)
woe_df- 코드를 보면 각 온도 범주값별로 target값의 평균값을 Good, Bad로 확률값을 대비하여 만들어주고 식을 적용하는 것을 볼 수 있다.

- 산출한 woe값은 다시 데이터프레임에 저장하면 된다.
# Map the WOE values back to each row of data-frame
df.loc[:, 'WoE_Encode'] = df['Temperature'].map(woe_df['WoE'])
df
9. Probability Ratio Encoding
Probability Ratio Encoding은 WoE와 많이 유사하고 유일한 차이점은 좋고 나쁜 확률에 대한 비율만 사용한다는 것이다.
P(Good)/P(Bad)의 확률값만 사용하게 되며, 만약 Bad의 확률이 0이 나오면 안되기 때문에 임의의 매우 작은 값을 대신 사용한다. Bad의 확률에 0 대신 임의의 매우 작은 값을 사용하는 것은 WoE에서도 마찬가지긴 하다.
# We calcuate probablity of target = 1 i.e. Good = 1 for each category
pr_df = df.groupby('Temperature')['Target'].mean()
pr_df = pd.DataFrame(pr_df)
#Rename the column name to 'Good' to Keep it consistent with formula for easy understanding
pr_df = pr_df.rename(columns = {'Target':'Good'})
# Calculate Bad probability which is 1 - Good probability
pr_df['Bad'] = 1 - pr_df.Good
# We need to add a small value to avoid divide by zero in denominator
pr_df['Bad'] = np.where(pr_df['Bad'] == 0, 0.000001, pr_df['Bad'])
# compute the Probability Ratio
pr_df['WoE'] = pr_df.Good/pr_df.Bad
pr_df
- 만든 값은 WoE에서 넣어주는 것과 동일한 형식으로 넣어주면 된다.
# Map the Probabilty Ratio values back to each row of data-frame
df.loc[:, 'PR_Encode'] = df['Temperature'].map(pr_df['PR'])
df
10. Hashing
해싱은 범주형 변수를 더 높은 차원의 숫자값으로 변환한다. 범주형 변수값의 벡터 사이의 거리는 변환된 수치 차원 공간에 의해 대략적으로 유지된다. 해싱을 하면 one hot encoding을 사용한것보다 차원수가 훨씬 적다. 즉 feature의 개수가 훨씬 적다는 것이다. 그래서 이 방법은 범주형 데이터의 카디널리티가 많이 높을 때 유리하다.
11. Backward Difference Encoding
이 인코딩은 level에 대한 종속 변수의 평균을 이전 level에 대한 종속 변수의 평균과 비교한다. ordinal, nominal 범주형 변수 둘다 모두 사용이 가능하다. 범주형 변수의 값 종류의 개수가 K개라면 K-1개의 더미 변수의 순서로 회귀로 적용된다.
12. Leave One Out Encoding
이 인코딩 방법은 target encoding과 비슷하지만 outlier들을 줄이기 위해 level에 대한 target의 평균값을 계산할 때 현재 행의 target을 제외한다.
13. James-Stein Encoding
이 인코딩으로 인한 변수 값은 가중치가 포함된 평균으로 적용된다.
관측된 feature 데이터의 평균 target 값이다. 평균을 전체 평균으로 축소한다는 데 무슨 말인지는.. 잘 모르겠다.
이 인코딩은 target 베이스의 encoder이다. 이 인코딩은 정규 분포에 대해서만 정의되었다.
14. M-estimator Encoding
이 인코딩은 target encoder의 간단한 버전이다. 이것은 정규화의 힘?을 나타내는 하이퍼 파라미터가 한개뿐인 m이 이다. m 값이 높을수록 수축이 더 강해진다. m 값의 권장량은 1~100사이의 값이다.
수축이 더 강해진다는 것은 값의 분포를 좀 평균적으로 좁혀준다는 의미인것 같다.

마지막으로 범주형 변수에 대해 어떤 인코딩 방식을 사용할 것인지에 요약한 플로우 차트를 소개하며 내용을 마무리한다.

참고 문서
https://towardsdatascience.com/all-about-categorical-variable-encoding-305f3361fd02
All about Categorical Variable Encoding
Most of the Machine learning algorithms can not handle categorical variables unless they are converted to numerical values and many…
towardsdatascience.com
One-Hot Encoding is making your Tree-Based Ensembles worse, here’s why?
Optimizing Tree-Based Models
towardsdatascience.com