
엘라스틱서치는 http 프로토콜로 접근이 가능한 REST API를 지원한다.
그래서, 다양한 언어에서 따로 구현체가 존재하지 않더라도 쉽게 엘라스틱서치를 접근해 검색엔진 시스템을 구축할 수 있다.
오늘은 엘라스틱서치에서 제공하는 다양한 REST API 중에 기본적인 4가지 종류의 API에 대해서 알아보도록 하자. API 요청을 하기 위해서 엘라스틱서치 서버의 HTTP 통신을 위한 기본적인 포트는 9200 포트를 사용한다.
먼저 문서를 색인하기 위해서는 문서의 그릇을 나타내기 위한 인덱스를 생성해야 한다.
여기서 잠깐!
영어로 된 문서에서는 색인을 표현하기 위해 index와 indexing, indices라는 용어가 사용되는데 IR이나 루씬에서 언급되는 index라는 단어와는 약간은 다른 엘라스틱서치의 표현으로 사용되고 있다.
index : 색인 데이터
indexing : 색인하는 과정
indices : 매핑 정보를 저장하는 논리적인 데이터 공간
엘라스틱서치는 편의성을 위해 스키마리스라는 기능을 제공하는데 이 말은 인덱스를 생성하지 않고 문서를 추가하더라도 자동으로 인덱스를 생성해주는 기능이다. 엘라스틱서치는 최초 색인시에 인덱스의 존재 여부를 확인하고 만약 인덱스가 존재하지 않으면 문서 내용을 기반으로 인덱스를 자동 생성해서 문서 색인을 시작하게 된다.
하지만..
스키마리스 기능은 가급적이면 사용하지 말자.
편리한 기능이기는 하지만 이는 성능과 밀접한 연관이 있기 때문에 특수한 상황에서만 사용해야 한다.
스키마리스 기능을 꼭 사용해야 한다면 데이터 구조 및 검색 방식을 확실히 이해해야 한다.
먼저 인덱스를 생성하지 않고 문서를 추가하는 경우 어떻게 보이는지 확인해보자.
실습을 위해서 REST API를 테스트할 수 있는 도구가 필요한데, 전 컨텐츠에서 보여줬었던 도커 기반 설치 내용을 기반으로 키바나의 Dev Tools를 이용해서 실습을 해볼것이다. 필자가 도커를 재설치해 컨테이너를 생성한 관계로 엘라스틱서치, 키바나의 버전은 7.16.2로 진행되었다.

다음과 같이 movie 인덱스가 생성되었고 _id가 1인 문서가 생성된 것을 볼 수 있다.
이 movie 인덱스를 다음과 같이 조회해보자.
GET /movie
결과 json을 확인해보면 mappings 에서 필드별 타입을 볼 수 있다. 각 타입들은 문자열 값으로 색인시에 기본적으로 keyword 타입과 text 타입을 동시에 갖는 멀티필드 기능으로 구성된다. 하지만, 항상 이렇게 설정되는 것은 필드별로 사용하지 않는 필드 타입 색인으로 인해 비효율적인 공간 차지와 색인 성능 저하가 발생하게 된다. 그래서 실무에서는 필드의 타입을 각각 지정을 해주고, 특히 검색을 위해서 문서의 텍스트를 토큰별로 잘라내는 분석기에 대한 타입을 지정해주는 것이 필수적이다.
따라서, 스키마리스 기능은 가급적이면 사용하지 말도록 하자.
엘라스틱서치를 운영할때 스키마리스 기능을 아예 disable 시켜줄수도 있는데, 노드 설정 파일에서 action.auto_create_index를 false로 설정할 경우에 자동으로 인덱스가 생성되지 않는다.
또한, 인덱스별로 index.mapper.dynamic을 false로 설정하면 특정 필드의 자동 매핑 생성을 비활성화할 수 있다.
elasticsearch7에서부터는 위 기능이 삭제되었고, 인덱스별로 필드 자동 매핑을 못하게 하기 위해서는 mappings를 정의할때 다음과 같은 필드를 추가하면 된다.
{
"mappings": {
"dynamic": false
}
}이렇게 설정하면 새로운 필드가 있을때 자동 매핑이 되지 않으며, _source 필드에서는 그대로 조회할 수 있다.
1. 인덱스 관리 API
이제 스키마리스로 색인을 생성하는 것이 안좋다는 것을 알았으니, 인덱스를 명시적으로 관리하는 API에 대해 알아보자.
인덱스 조회
인덱스 조회는 앞에서 먼저 확인해보았듯이,
GET /index_name로 조회하면 된다.
인덱스 생성
인덱스 생성시 매핑이라는 설정으로 문서와 문서에 포함된 필드, 필드 타입 등을 세세하게 지정하는 것이 가능하다. 주의해야 할 점은, 한 번 생성한 매핑 정보는 변경이 불가능하다. 그래서 잘못 생성한 인덱스의 매핑 정보가 있으면 인덱스를 다시 만들어야 한다.
인덱스 생성시 다음과 같이 PUT 메소드와 인덱스명으로 인덱스를 생성할 수 있다.
PUT /index_name
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 2
},
"mappings": {
"properties": {
"movieCd": { "type": "integer" },
"movieNm": { "type": "text" },
"movieNmEn": { "type": "text" },
"prdtYear": { "type": "integer" },
...
}
}
}
# response
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "index_name"
}엘라스틱서치에서 필드별로 다양한 형태의 데이터 타입을 제공할 수 있다. 단순히 키워드를 저장하고 싶다면 keyword, 문자열에 형태소 분석을 해서 토큰단위로 저장하고 검색할 수 있게 하려면 text 타입을 쓰면 되고, 값이 정수라면 integer로 간단하게 설정할 수가 있다. 한국어 형태소 분석기를 쓴다던가 다른 다양한 필드 타입을 사용하는 것은 다음에 알아보도록 하자.
인덱스 삭제
인덱스 삭제는 간단하게 DELETE 메소드로 인덱스명만 입력하면 된다.
DELETE /index_name
# response
{
"acknowledged" : true
}
2. 문서 관리 API
문서 관리 API는 실제로 문서를 색인, 조회, 수정, 삭제를 지원하는 API이다. 엘라스틱서치는 기본적으로 검색엔진이기 때문에 검색을 위해 다양한 검색 패턴을 지원하는 Search API가 별도로 존재한다. 문서 관리 API는 문서의 ID를 기준으로 문서를 다뤄야 하는 경우에 사용하게 된다.
문서 관리 API는 단일 문서 API와 멀티 문서 API가 존재한다.
단일 문서 API의 종류는 다음과 같다.
Index API : 한 건의 문서를 색인한다.
Get API : 한 건의 문서를 조회한다.
Delete API : 한 건의 문서를 삭제한다.
Update API : 한 건의 문서를 업데이트한다.
멀티 문서 API는 클러스터에 한 번의 요청에 많은 양의 문서를 처리하기 위해 존재하는 기능이고, 성능상 검색엔진을 실제로 운영할 때 많이 도움이 되는 기능이다.
Multi Get API : 다수의 문서를 조회한다.
Bulk API : 대량의 문서를 색인한다.
Delete By Query API : 다수의 문서를 삭제한다.
Update By Query API : 다수의 문서를 업데이트한다.
Reindex API : 인덱스의 문서를 다시 색인한다.
이런 종류들의 API가 존재하는데 여기서는 단일 문서 API에 대해서만 간단히 알아보자.
문서 생성 (Index API)
문서 생성은 POST 메소드로 다음과 같이 만들면 된다.
POST /index_name/_doc/ID예시 문서를 색인해보고 결과를 확인해보면 다음과 같이 나온다.
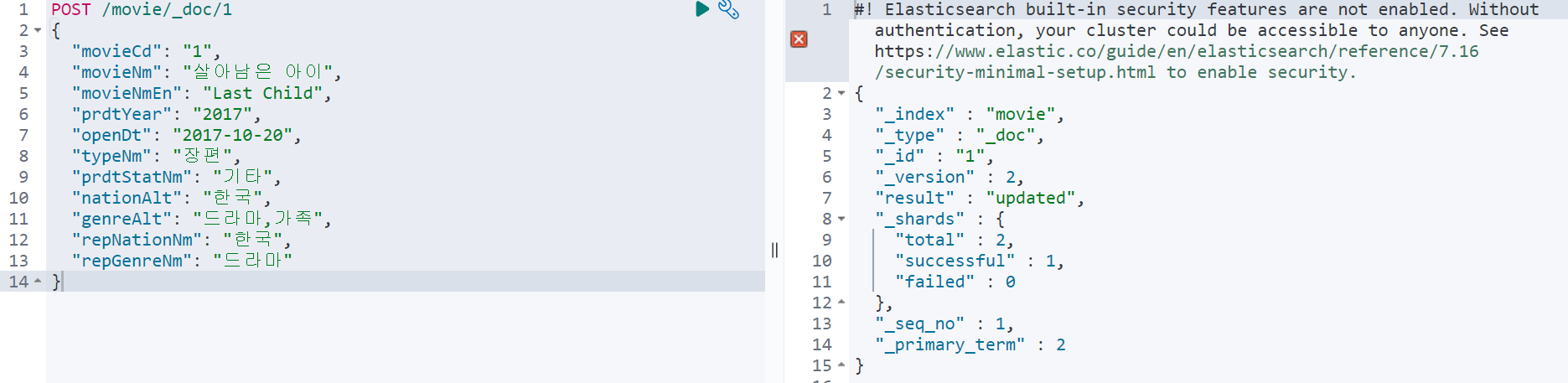
여기서 ID를 지정하지 않고 문서를 생성하면 어떻게 될까?

보이다시피 _id가 임의의 UUID로 생성된 것을 볼 수 있다. 언뜻 보면 자동으로 ID를 생성해줘서 편리한 기능같지만 인덱스와 문서를 운영하는데 있어서 문서 ID를 가지고 추적하여, 수정이나 삭제, 조회를 하게 되는 경우가 있는데 자동으로 ID가 생성되면 사실상 ID로 문서를 추적하는 것이 사실상 불가능 하기 때문에 ID는 직접 선언하여 색인하는 편이 바람직하다.
문서 조회 (Get API)
문서 조회는 다음과 같이 GET 메소드로 문서 ID로 쉽게 조회된다.
GET /index_name/_doc/ID
문서 삭제 (Delete API)
다음으로는 색인된 문서를 삭제해보자.
문서 삭제는 DELETE 메소드로 인덱스 이름과 문서 ID를 넘겨주면 된다.
DELETE /index_name/_doc/ID
문서 수정 (Update API)
다음으로 색인된 문서를 수정해보자.
문서의 필드중 일부를 바꾸려면 POST 메소드로 다음과 같이 작성하면 된다.
POST /index_name/_update/ID
{
"doc": {
"field":"value",
...
}
}
엘라스틱서치 document를 보면 위와 같이 하지 않고, 문서를 가져와서 update 할 때 쓸 스크립트와 파라미터를 넘겨주면 인덱싱을 해준다는 소개를 볼 수 있는데, 기존 문서를 완전히 바꾸려면 index API를 사용하라고 안내를 하고 있다. 스크립트 형식 작성 방법은 다음 링크를 확인해보자. 그래서 update api는 사실상 거의 쓰지 않을 것 같고, 실제로는 문서를 직접 다시 색인하는 방식으로 사용하게 될 것 같다.
3. 검색 API
다음으로 색인한 인덱스에 있는 문서를 검색해보자.
검색의 API 사용 방식은 다음과 같이 크게 두 가지로 나뉜다.
1. URI 방식의 검색 질의
HTTP URI 형태의 파라미터를 URI에 추가해 검색하는 방법
2. Response Body 방식의 검색 질의
RESTful API 방식인 QueryDSL을 사용해 요청 본문(Request Body)에 질의 내용을 추가해 검색하는 방법
2번째 방식이 1번째 방식보다 제약사항이 적어 편리하기 때문에 현업에서는 2번째 방식을 선호한다.
URI 방식은 간단한 쿼리나 디버깅을 할때 간편하게 사용하는 경우가 종종 있다.
간단한 표현식이라면 두 가지 형식을 섞어서 사용하는 것도 가능하다.
예를 들어, Query는 URI에 넣고 나머지 기능을 JSON 형태로 사용해도 된다.
다음은 2017년에 개봉된 영화를 영화 제목을 기준으로 정렬해서 보여주는 예시다.
GET /movie/_doc/_search?q=prdtYear:2017&pretty=true
{
"sort": {
"movieCd": {
"order": "asc"
}
}
}
쿼리의 조건이 여러개가 필요하거나, 통계를 위한 aggregation 쿼리 등 복잡한 쿼리를 작성하려면 Response Body 방식의 검색 질의를 사용하면 된다.
URI 방식의 검색 질의
ID로 문서를 검색하는 건 위에서 해보았다.
이제 URI 방식으로 키워드를 통한 문서 검색을 한번 해보도록 하자.
다음과 같은 형식을 통해 쿼리를 만들어서 검색 요청을 할 수 있다.
POST /index_name/_search?q=keyword
q=키워드 형식으로 검색을 하게 되면 인덱스에 포함된 모든 필드를 대상으로 검색을 수행한다.
URI 방식을 사용할 때, 특정 필드에 대해 검색을 하고 싶다면 다음과 같이 하면 된다.
POST /index_name/_search?q=fieldName:keyword
Request Body 방식의 검색 질의
Request Body 방식을 사용하면 URI 방식보다 가독성이 좋고, 여러 가지 복잡한 조건의 쿼리를 쉽게 처리할 수 있다. URI에 들어가던 쿼리 값을 query 필드에 넣고 나머지 값도 필요한대로 사용하면 된다.
POST /index_name/_search
{
size: , # 몇개를 반환할 지 정한다. default: 10
from: , # 어느 위치부터 반환할지 결정한다.
_source: , # 특정 필드만 결과로 반환하고 싶을때 사용한다.
sort: , # 특정 필드를 기준으로 정렬한다.
query: {
# 검색 조건을 정의한다.
},
filter: {
# 검색 결과 중 특정 값을 다시 걸러서 보여준다.
# score 값을 정렬할 때는 사용되지 않는다.
}
}이 검색 방식을 사용하는 자세한 방법은 이후에 다시 소개하도록 하겠다.
4. 집계 API
과거에는 통계 작업을 위해 루씬이 제공하는 패싯 기능을 많이 사용했었다. 하지만 패싯 기능은 기본적으로 디스크 기반으로 동작했고, 분산 환경에서는 적절하지가 않았다. 그래서 엘라스틱서치는 독자적인 집계(Aggregation) API를 만들게 되었다. 이 API는 기본적으로 메모리 기반으로 동작하기 때문에 대용량 데이터 통계 작업을 가능하게 했다.
그리고 기존 패싯 기능에서는 할 수 없었던 작업 처리를 할 수 있게 해주었다.
데이터 집계
먼저 하나의 그룹핑으로 집계 쿼리를 만들어 보자.
집계 API는 검색 API와 동일하게 _search 엔드포인트로 질의를 만들수 있다.
예시로 movie 인덱스에 terms 키워드를 이용해 genreAlt라는 필드의 데이터를 그룹화를 해보자.
POST /movie/_search?size=0
{
"aggs":{
"genre": {
"terms":{
"field":"genreAlt"
}
}
}
}
# response
{
...,
"aggregations: {
"genre": {
...,
"buckets": [
{
"key": "드라마",
"doc_count": 19856
},
...
]
}
}
}집계 결과를 보면 buckets라는 구조 안에 그룹화된 데이터가 포함돼 있다.
엘라스틱서치의 집계가 강력한 이유는 버킷 안에 다른 버킷의 결과를 추가할 수 있다는 점이다. 그래서 이것을 활용해 다양한 집계 유형을 결합, 중첩, 조합하는 것이 가능해졌다.
다음의 예시처럼 2계층으로 집계되도록 만들 수 있는 것이다.
POST /movie/_search?size=0
{
"aggs":{
"genre": {
"terms":{
"field":"genreAlt"
},
"aggs": {
"nation": {
"terms": {
"field": "nationAlt"
}
}
}
}
}
}질의를 해보면 bucket안에 bucket이 있는 걸 볼 수 있다. 내용이 길어 결과 그림은 생략했다.
집계 API의 기능은 다음에 한번 다시 자세하게 다뤄보도록 하겠다.
데이터 집계 타입
집계 기능은 크게 세가지 타입의 집계 방식을 제공하고 있다.
버킷 집계 (Bucket Aggregation) : 집계 중 가장 많이 사용하는 방식으로 문서의 필드를 기준으로 버킷을 집계한다.
매트릭 집계 (Metric Aggregation) : 문서에서 추출된 값을 가지고 sum, max, min, avg를 계산한다.
파이프라인 집계 (Pipeline Aggregation) : 버킷에서 도출된 문서들을 다른 필드의 값으로 재분류한다. 한마디로 집계 결과로 다시 집계하는 방식이다. 집계가 패싯보다 강력한 기능인 이유이다.
마치며
이렇게 해서 인덱스를 생성하고 문서 단위로 편집하고 문서를 검색하고 집계하는 것을 간단하게 알아보았다.
다음으로는 인덱스 mappings에 지정할 수 있는 필드 타입의 종류에 대해서 알아보겠다.
참고자료
'database > elastic search' 카테고리의 다른 글
| [elastic search] 엘라스틱서치의 기본적인 구조와 개념 (0) | 2021.10.12 |
|---|---|
| [Elastic search] 엘라스틱서치의 개요, 도커 기반 설치하기 (0) | 2021.06.12 |