
지금 내 회사의 팀에서는 mongodb를 적극적으로 사용중이다.
기존에는 replica set으로만 운영해도 충분했다.
하지만 쌓여가는 데이터와 쿼리수가 점점 많아지면서,
신규로 샤드 클러스터를 구축하여 데이터를 이관해 사용하게 되었다.
이렇게 샤드 클러스터를 운영해보면서 공부하고 느낀 내용을 주제로 글을 써보려고 한다.
이 글은 mongodb 4.4.x 버전 기준으로 작성되었다.
mongodb DB 샤딩 구조

mongodb shard cluster의 구성 요소는 3가지로 이루어져 있다.
1. mongos
쿼리 라우터.
쿼리가 유입되는 진입점으로 data가 존재하는 샤드로 쿼리를 날려주는 인터페이스의 역할을 한다.
2. config server
shard cluster에 대한 메타데이터를 가지는 서버로 샤드와 컬렉션, 청크들에 대한 정보를 가지고 있어
쿼리 라우터가 이 서버의 메타 정보를 기반으로 샤드에 쿼리를 날려주게 된다.
이 서버가 죽으면 클러스터 전체를 사용하지 못하므로, 적절하게 레플리카셋을 설정해줘야 한다.
3. shard
실제로 데이터가 존재하는 mongodb 서버.
여러 개의 샤드로 운영하며, 데이터가 매우 많더라도 '이상적으로는' 데이터가 샤드별로 잘 분배되어
쉽게 scale-out을 할 수 있다.
샤드 클러스터 구성을 완료하게 되면,
컬렉션별로 무조건 샤딩이 되는 것은 아니고 설정을 통해 샤딩 컬렉션을 생성해줘야 한다.
컬렉션 샤딩하기
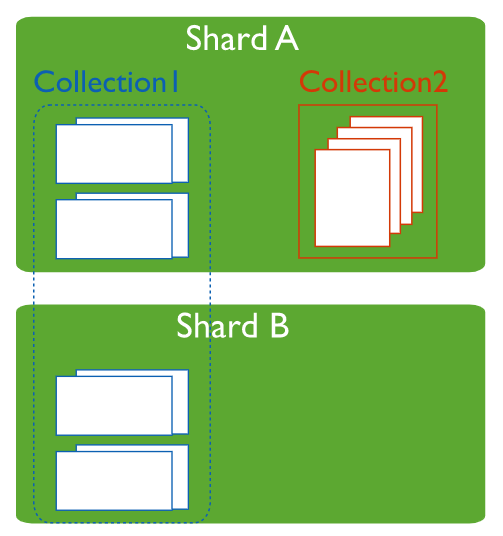
컬렉션 샤딩은 청크 단위로 문서를 그룹핑하여 각 샤드로 밸런싱이 되는 형태이다.
그리고 청크별로 문서 집합을 묶어주는 역할을 하는것이 shard key이다.
컬렉션에 shard key를 만들어주기 위한 두가지 전략이 있다.
1. ranged index
범위 기반의 인덱스를 샤드 키로 선택할 수 있다.
다음의 그림 예시를 보자.

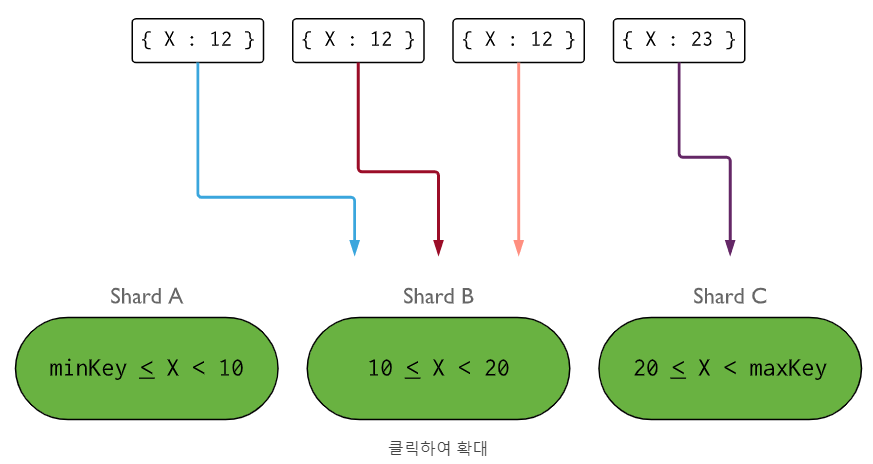
1) 어떤 컬렉션에 값이 많이 저장되어 있고, x라는 필드가 있다.
2) x 필드값의 범위가 가령 -100 ~ 200 까지이고, x 필드를 인덱스로 설정했다
3) x 인덱스를 샤드 키로 지정한다.
4) 문서들이 x 필드값의 범위안에 고르게 분포한 경우 위처럼 chunk는 4개가 생성될 수 있겠다.
샤딩 컬렉션은 초기에 청크를 1개부터 시작한다.
다음으로, 청크 사이즈가 기준값을 초과하면 청크를 새로 추가하여 청크를 샤드들에 골고루 분포시킨다.
그리고 각 청크의 범위에 따라서 데이터가 마이그레이션되기 시작한다.
ranged index를 샤드키로 선택하려면 3가지를 중점적으로 고려해야한다.
1) 샤드 키의 카디널리티

이 예시로 보면, X 라는 필드의 값이 문서별로 다양하지 않고 극단적으로 1이나 2만 갖고 있다고 한다면
청크는 쪼개고 싶어도 더 쪼개질수도 없고 특정 샤드들에 문서 수가 몰릴수가 있다.
청크가 여러 개로 생성되게 하고 싶다면 값의 분포가 다양한 필드를 사용해야 한다.
2) 샤드 키의 문서별 값 빈도
청크가 여러개로 쪼개질 수 있다고 해도 특정 범위의 값이 다른 값에 비해 발생빈도가 높은 경우에는
이 경우에도 청크별로 사이즈가 다르고 특정 샤드에 데이터가 몰릴수가 있다.
3) 샤드 키가 단조롭게 증가함

청크의 범위는 가장 작은 값 minKey, 가장 큰 값 maxKey를 가지고 있다.
적재되는 문서들의 값이 단조롭게 증가하는 경우에 위처럼 하나의 샤드의 청크에 write 연산이 몰려 병목 지점이 된다.
이후에 청크는 split되고 밸런싱도 되긴 하겠지만 특정 샤드에 쪼개져 전달될 청크가 몰려서 생기는 것도 부담이다.
2. hashed index
샤드 키로 선택할 키가 단조롭게 증가하거나 특정 범위에 가까이 분포하는 경우에는 hashed index를 사용할 수 있다.
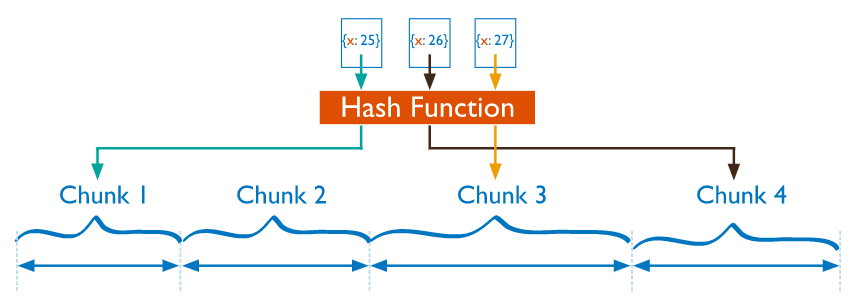
이 그림의 예시처럼 hashed index는 mongodb가 가진 해시 알고리즘에 의해
해시 값으로 변경되어 넓은 범위로 골고루 분포될 수가 있다.
마땅한 샤드키가 없는 경우에는 _id 인덱스의 hashed index로 샤드 키를 설정할 수 있다.
Tip.
실제로 hashed index로 샤딩 컬렉션을 생성하고 적재를 해보면
청크가 분리되고 마이그레이션이 완료되더라도 각 샤드별로 문서 수 분포가 그다지 고르지 못하다.
아마도 청크가 분리될때의 자동으로 되는 범위 설정이 고르지 못한 것 같다.
N개의 샤드에 문서수가 거의 1/N로 고르게 분포시키고 싶다면 샤딩 컬렉션을 생성할 때
numInitialChunks 옵션을 넣으면 된다.
이 옵션을 사용하면 컬렉션의 초기 청크 수를 직접 지정할 수 있고, 각 청크별로 범위가 고르게 분포된다.
#커맨드 예시
db.adminCommand({shardCollection:"test.testCollection",key:{_id:"hashed"},numInitialChunks:1000})샤딩 컬렉션 생성 과정
# test 데이터베이스의 product 컬렉션을 샤딩하기
# 1. DB 선택하기
use test
# 2. 데이터베이스 생성 후, DB 샤딩 사용 설정
sh.enableSharding("test")
# 또는
sh.enableSharding("test", primary shard id) # primary shard 직접 선택
# 3. 컬렉션 생성
db.createCollection("product")
# 4. 컬렉션 샤드키 인덱스 생성
db.product.createIndex({"category":1})
# 5. 컬렉션 샤딩
sh.shardCollection("test.product", {"category":1})
# 6. 컬렉션 샤딩 정보 확인
sh.status()
primary shard의 역할
샤딩 사용을 설정한 DB에 샤딩되지 않은 컬렉션은 데이터 적재시 primary shard에 적재되게 된다.
그러므로 DB를 생성하고 어느 샤드를 primary shard로 할지도 서버 자원에 따라 잘 선택해야 한다.
샤딩 컬렉션 운영시 유의사항
1. shard key를 잘 선택해 최대한 분산 쿼리가 발생하지 않도록 하기
mongodb를 샤드 클러스터로 구성하는 가장 큰 이유중 하나가 부하 분산이다.
샤딩 컬렉션을 적재할때의 고려할 사항은 위에서 거의 설명이 된 것 같다.
하지만, shard key를 선택하는 것은 컬렉션 조회 부하 관점에서도 고려가 필요하다.
다음의 그림을 보자.

클라이언트가 쿼리 라우터를 통해 샤드로 쿼리를 날릴 때는
쿼리에 shard key가 존재하느냐 안하느냐에 따라 양상이 달라진다.
1) 쿼리에 shard key 조건이 포함되는 경우
쿼리 라우터는 해당 샤드키 범위에 있는 샤드 서버로만 쿼리를 전달하고 결과를 가져온다.
2) 쿼리에 shard key 조건이 없는 경우
동일한 쿼리를 모든 샤드에 날리고 결과값을 받아온다.
이는 샤드키가 아닌 인덱스를 쿼리에 사용하더라도 동일하게 전체 샤드에 질의한다.
극단적인 예시로 들면 샤드 3개가 있다고 했을때,
초당 9만 쿼리를 샤드키 조건이 없는 경우에는 3개의 샤드 모두 9만 쿼리의 부하를 견뎌야 하지만
쿼리에 다양한 범위로 샤드키 조건 값이 있는 경우 이상적으로는 각 샤드당 3만 쿼리의 부하만 처리하면 된다.
이렇기 때문에 shard key를 선택할 때는 자주 조회할 쿼리의 조건으로도 고려가 되어야 한다.
2. 컬렉션 샤딩이 필요한 경우 미리 컬렉션 생성시 샤딩 컬렉션으로 생성하기
이미 많은 문서가 적재된 상태에서도 기존의 인덱스나 새로운 인덱스를 생성하고나서 샤딩 컬렉션으로 전환을 할 수도 있긴 하다.
하지만, 기존 primary shard에서 샤딩 후 청크와 문서들이 다른 샤드로 넘어가기 시작해
기존 샤드에서 문서가 삭제되더라도 디스크 공간은 그대로 유지되어 낭비되게 된다.
-> mongodb는 wiredtiger 스토리지 엔진을 사용하면서, 할당된 디스크 공간은 문서를 지우더라도 재사용되기 위해 그대로 유지가 된다.
초기에 컬렉션을 샤딩해놓고 넓은 기간을 거쳐 문서가 적재된다면 샤드별로 청크 생성과 밸런싱을 거치면서 데이터가 고르게 분포될수 있다.
3. compact 명령어 활용하기
3번과 이어지는 내용인데,
삭제된 문서양이 매우 많은 경우에 할당된 디스크 공간을 명시적으로 해제시켜야 할 때 compact 명령어를 사용한다.
compact를 수행할 샤드의 레플리카셋 각각에 접속하여 명령어를 입력하여 디스크 공간을 확보한다.
use test
db.runCommand({"compact":"product"})primary 서버의 경우 force: true 옵션을 추가해서 커맨드를 수행시킬수는 있다.
근데 메뉴얼에는 compact 실행시 crud operation은 block을 하지 않는다고 되어 있지만,
실제로 해보면 해당 서버가 recovery 상태로 들어가면서 서버에 대한 모든 오퍼레이션이 동작하지 않으므로,
secondary 서버별로 각각 수행한 후, primary 서버를 stepDown 시켜 secondary로 내린다음에 실행시키기 바란다.
또한, compact 명령어가 특정 멤버에서 수행중인 경우 클러스터 전체에서 다음의 명령어들이 사용이 불가능하다.
1) db.collection.drop()
2) db.collection.createIndex()
3) db.collection.dropIndex()
위의 사항들을 고려한다면 DB를 운영중에도 compact를 진행할 수 있다.
4. 특정 샤드가 디스크 공간이 모자라질 정도로 방치하지 않고 제때 scale-out 하기
위에서 언급했듯이 mongodb 스토리지 엔진 특성에 따라서 샤드를 추가해 데이터가 밸런싱되더라도
compact 작업을 하지 않는 이상 기존 샤드들의 디스크 공간은 변화가 없다.
그러니 데이터가 더 많아질것 같다면 미리미리 서버를 추가하자.
5. 컬렉션 샤딩시 renameCollection, lookup이 되지 않는다.
mongodb 5.0 버전부터는 샤딩 컬렉션도 rename이 가능해지긴 했다.
Sharded CollectionsStarting in MongoDB 5.0, you can use the renameCollection command to change the name of a sharded collection. The target database must be the same as the source database.
마치며
아직 mongodb 샤드 클러스터를 사용하는것이 익숙치 않아 여러번 장애를 냈었던 것 같다.
클러스터 전체를 내렸다가 올려본적이 한두번이 아니다.
이 글을 보시는 분들도 mongodb를 standalone이나 레플리카셋만 쾌적하게 이용하다가
샤드 클러스터로의 전환 후 운영하는것이 생각보다 너무 어렵고 장애 지옥이 펼쳐질 수도 있으니 조심하기 바란다.
많이 배우는 기회가 됐다고 긍정적으로 생각해야지..
이어서 mongodb 주제의 다음글은 현재 겪고 있는 문제에 대한 해결과 관련된 글이 될 듯하다.
참고 자료 링크
'database > mongodb' 카테고리의 다른 글
| [MongoDB] db.collection.count() 쿼리 수행 (0) | 2021.06.08 |
|---|